
Reproducibility in automated chemistry laboratories using computer science abstractions
本来晚上说买一杯咖啡,但担心睡不着,最后点了蜜雪的蓝莓果粒茶,然后,然后就是大半夜没睡着,遂决定记录今天阅读的论文。。。
论文总结
这篇综述主要内容是对自动化学实验室语言的趋势分析,讨论的核心问题非常直接:自动化化学正在快速发展,但“能跑起来”并不等于“能被别人稳定复现”。很多平台已经能把实验流程写成可执行代码,也能在不同设备之间迁移协议,但论文指出,当前社区过度强调“可迁移性(Transferability)”,相对忽视了“可复现性(Reproducibility)”的严谨定义与工程保障。作者的主张是:实验自动化语言必须把“抽象(Abstraction)”用在正确层级,并且在语言层、接口层、执行层都显式处理不确定性、上下文和失败模式,否则抽象越高级,对实验结果可复现性的技术债务就越重。
论文首先澄清了几个经常混用的术语。作者把 Repeatability 与 Reproducibility 区分为两个层面:前者更接近“同一装置、同一条件下的方差控制”,后者更接近“不同实现之间结果分布的重叠程度”。这个定义特别有价值,因为它把“复现”从口号变成了可统计比较的对象。自动化场景里,很多人默认“同一段代码在两台机器上执行”就算可复现,但作者提醒,真正应比较的是结果分布,而不是指令字符串。只要硬件特性、控制精度、材料状态、环境条件发生变化,结果分布就可能偏移。也就是说,抽象允许了修改,修改就会影响分布,复现性必须在“允许修改的边界”内被定量验证。论文中还提到了互操作性(Interopearability)和可迁移性(Transferability),前者指的是不同系统交换并直接使用信息的能力,而后者是指代码被移动到另一个平台并成功执行的能力。用化学实验室中的例子来说,如果两个不同的设备都使用同样的API(比如遵循SiLA标准),那么他们就具有互操作性;如果代码中缺乏对物理环境的适应逻辑(比如没有考虑另一个设备中被“死体积”吞掉的原料),那么即使既有互操作性也不具有可迁移性。
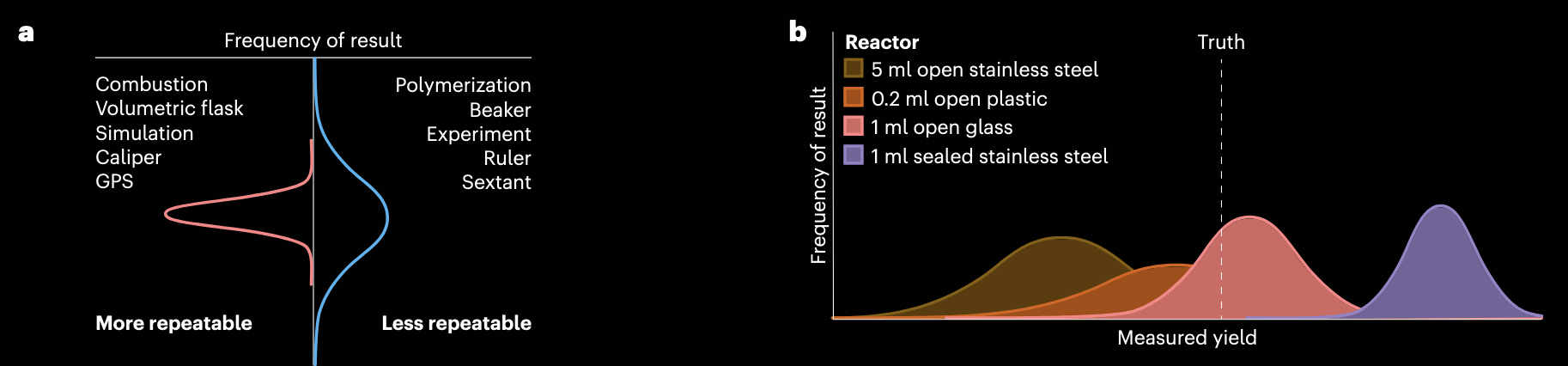
左图表示可重复性,如果方差越小,图像越窄,可重复性越强;右图则表示可复现性,如上文所说,如果改变某个硬件条件或者环境条件,不同实现之间结果分布重叠程度越高,可复现程度就越强。
在此基础上,论文把“抽象”重新定义为一种“在特定上下文中声明可替代性”的行为。比如把移液器、注射泵、料斗都抽象成 “Transfer tool”,在语义上等于说它们在相关上下文里可以互换。问题在于,化学实验的上下文高度敏感,很多看似次要的实现差异会变成主导因素:死体积、空气间隙、液体挥发性、接触方式、背压、污染路径、阀门切换时序、清洗策略等,都可能改变真实投料量和物料历史。于是,“同一抽象接口”并不自动推出“同一实验效果”。作者举了 χDL 跨平台执行中的例子:高层都写相同的加液抽象,但不同系统实际加液行为不同,产物分布就不同;同理,结晶步骤采用不同实现,收率差异显著。
为了让这个问题可工程化,论文引入了计算机科学里“合同(Contract)”与“接口(Interface)”的思想。每个实验步骤都可视为 “输入 $\rightarrow$ 动作 $\rightarrow$ 输出 $\rightarrow$ 错误” 的合同:需要哪些先决信息?保证什么后置状态?失败如何报告?副作用如何记录?作者强调,合同不是写得越宽泛越好,也不是越细越好。太宽泛会导致语义空洞(几乎无法约束行为);太细会导致系统高度耦合(Coupling),一换硬件就全部失效。尤其在自动化实验里,一个动作往往改变多个实体状态,例如 Transfer 不只改变目标容器,还会改变源容器余量、工具污染状态、阀路状态乃至后续步骤可行性。如果这些状态变化不进合同或不被外部机制追踪,复现性就会被“隐式副作用”侵蚀。
论文在这部分还强调了分包商(Subcontractor)机制。作者用 HPLC 的例子说明:主合同可以只约定“给定样品与方法,返回分析结果/状态”,但执行过程中涉及的阀门切换、进样时序、定位动作等能力,未必应该由 HPLC 控制器硬编码承担。更合理的方式是把这些能力作为“子合同”由外部模块传入,也就是把 Sample Valve Controller 这类组件当成分包商。这样做的核心价值是降低耦合:同一个主操作不必绑定某一类固定硬件实现,从而更容易迁移到不同平台。代价是每次调用主操作时,调用方都要准备并提供可用的分包商接口,系统集成复杂度会上升。换句话说,分包商不是为了让流程更“省事”,而是为了把“可迁移”建立在显式合同拼装上,而不是隐式假设上。
这里还有一个容易误解但论文并不矛盾的点:分包商负责“如何执行定位/阀控”等底层动作,而“去哪里(Source/Destination 该选谁)”这一语义决策应放在更高阶抽象中统一管理。论文在 Table 1 注释中明确指出,位置选择不应由 Transfer tool 负责,而应由能够同时协调“位置选择 + 物料转移”的上层抽象承担。也就是说,分包商不是决策者,而是执行者。
论文中关于耦合的讨论也很有启发。很多人以为多模块平台天然模块化,但作者指出,机械结构耦合、流路耦合、数据耦合、控制耦合都可能让系统脆弱。比如连续流系统在过程控制上通常更稳定,但流路常常高度串联,某个泵故障会级联影响下游全部单元;色谱等分离环节则同时影响样品、溶剂、废液、柱状态,耦合程度极高。如果编排语言没有把这些耦合关系“显化”,用户就只能在执行时被动发现问题。
下图是论文总结的几类使用抽象的可行路径: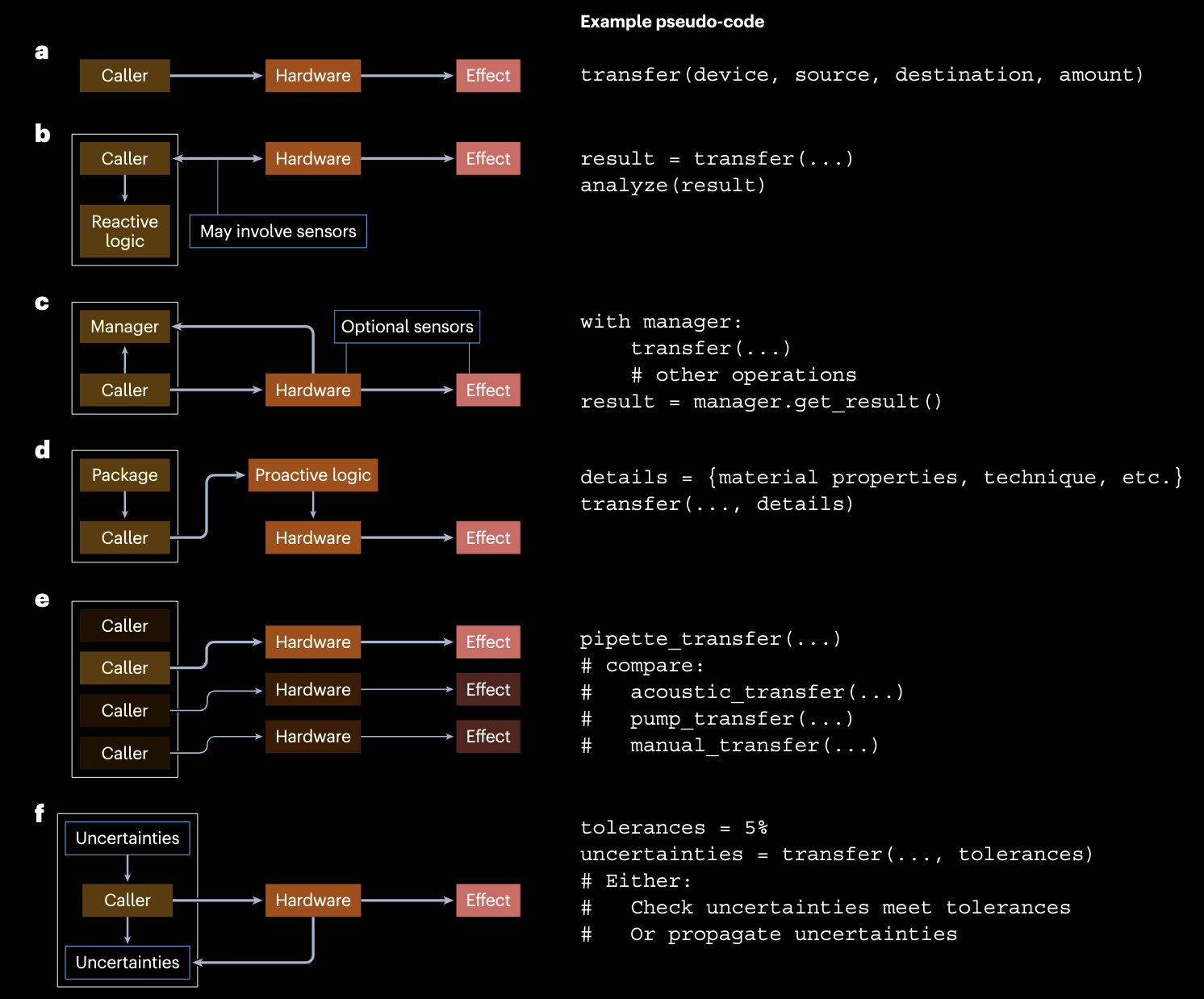
Reactive approaches(反应式/响应式):
每个操作不只返回 Success/Fail,而是返回更丰富的执行反馈,包括部分成功、状态变化、观测值与异常类型。这样上层流程可以根据实时反馈做分支控制和纠偏。其本质是把“实验执行现实”回流到协议语义中,而不是假设底层动作理想完成。对于化学实验这种高噪声系统,这比静态脚本更接近实际。Supervisor/Context Manager 机制:
作者建议把很多“跨步骤状态管理”从单步操作里解耦出来,交给独立监督进程处理,例如污染追踪、可达性检查、清洗插入、元数据记录、环境监控、故障隔离等。这样做可以降低单个操作接口的复杂度,同时把系统级保障放在统一位置,便于审计与维护。论文把这种思想类比到 Erlang 的“let it crash”哲学与 Python 的上下文管理器,强调错误处理不应都塞进原子动作内部,而应在更高层有可组合的治理逻辑。Interpretive approaches(解释式/富上下文执行):
即在操作触发时提供更多上下文信息(显式参数包或隐式数据库链接),让执行器根据设备能力自适应策略,必要时在多实现之间选择。这个方向与当前不少中心化调度架构相契合:设备不彼此强耦合,而通过中枢服务交换消息与状态。优点是可扩展、可演化;缺点是对数据模型、能力描述与解释器质量要求很高,而且“信息更多”不等于“行为等价”,如果能力声明不准确,仍可能出现隐藏偏差。Limited abstraction(受限抽象):
作者提出一个看似“保守”但实际很实用的策略:不要强行用一个 Transfer 覆盖所有传质技术,而是按真正可互换的实现分层抽象,必要时让用户显式选择 pipette_transfer、pump_transfer 等。这样会牺牲部分开箱即用互操作性,却能带来三项现实收益:问题可在执行前暴露、故障定位更直接、新方法原型更容易接入。其代价是明显的:需要社区持续维护一个高质量、可检索、文档完备的操作库,否则会退化成“版本碎片化地狱”。Emulating unreliability(显式建模不可靠性):
论文借鉴云计算和系统工程思路,提出两种做法:其一是按硬件能力做最低公分母执行模式,在跨平台复现实验时主动降级到共同能力区间;其二是把精度、偏差、容差等可靠性信息编码进语言对象,让“目标值”与“实际实现值”并存,而非只存一个名义数值。这个观点非常前沿,因为化学自动化最大的现实难题之一就是:很多设备在不同溶剂、不同黏度、不同挥发性条件下误差行为不同,且往往缺少系统标定数据。作者因此指出,完全前瞻式误差传播很难,结合随机抽检和监督机制的“事后验证”可能更务实。
论文还花了相当篇幅讨论“语言与生态”的未来。作者认为,自动化实验语言不可能只优化单一目标;除复现性外,还必须兼顾可读性、可写性、学习成本与执行效率。尤其面对不同任务形态:自治探索、自动优化、跨实验室验证,对语言表达的需求并不相同。前两者需要给系统更大策略自由度,后者则需要更严格、可审计、可比对的具体约束。这天然指向“多语言共存”而非“唯一通用语言”。与其追求一个巨型万能语言,不如建立少量高价值语言 + 可靠翻译器(Transpiler)的体系,让研究者可用熟悉表达进行设计,再通过可验证转换实现跨平台协作。论文中也提到了机器学习在编程语言翻译上的成功,未来可以基于大模型开发这样的语言翻译工具。
在硬件与工业接口层面,作者的判断也很现实:要求所有厂商统一能力和 API 几乎不可行,商业竞争本就依赖差异化功能。因而短期内最重要的不是“接口绝对统一”,而是“文档充分透明”:设备能做什么、不能做什么、参数语义是什么、数据格式如何解析,都应被完整公开。没有文档,再优雅的抽象也只是猜测;有了文档,社区至少可以构建可验证的桥接层。论文对这一点的强调值得高度认同,因为很多实验复现失败并非科学原理问题,而是接口黑箱与隐式假设导致的信息断裂。
文章最后把问题提升到科研组织层面:自动化实验结果在发表前,是否应像结构表征那样提供复现性证据?作者给出两条路径:一是跨实验室交叉验证,二是单实验室做可负担范围内的替换实验并报告结果分布重叠度。前者能促进协作但资金与组织门槛高;后者更易落地但验证边界有限。无论哪种路径,核心都在于把“复现性评估”从可选项变成标准流程,并且尽量前置到平台开发阶段,而不是论文提交前的临时补救。