
From PPO to GRPO
先强力安利一下西湖大学赵世钰老师的强化学习的数学原理课程,在B站就能搜到,上完这个课程,你对强化学习在做些什么以及强化学习最基础的算法也就有个大概的了解了,里面涉及的相关数学公式和定理有个大概了解即可,不需要太过关注背后严谨的证明过程(有兴趣且有足够的时间可以钻研)。
课程在讲完Actor-Critic算法之后就结束了,而现阶段RLHF以及AgenticRL中常用的,以TRPO为基础的算法并没有讲解。这里又再安利一下动手学强化学习这本书,GitHub链接放在下面,网页版就能浏览,有算法的原理讲解和具体实现,很适合强化学习的入门。
下面是我自己对基本强化学习算法的代码实现,其实和Hands-on-RL书中的基本相似,因为书中用的仿真环境是gym,我使用的是gymnasium,所以我修改了一些超参数。同时代码库中还有我强化学习的笔记,大家感兴趣可以翻看,有任何问题和意见可以给我留言提出!
回到博客的正题哈哈哈,我先假设你有TRPO的基础,从PPO算法讲起。PPO算法是对TRPO算法的一种改进,他相对于TRPO算法,实现起来更加简单,性能还有提升。PPO算法的实现主要有两种,一种是PPO惩罚,即是将KL散度放入目标函数中,使TRPO中的带约束条件的优化问题转变为无约束条件的优化问题,迭代过程中不断修改KL散度前面的系数。
- 设定限制策略之间差距的超参数:δ
- 按照以下规则更新 β:
- 若 kl > 1.5 δ,则增大惩罚系数:β ← β 2
- 若 kl < δ / 1.5,则减小惩罚系数:β ← β / 2
- 否则保持不变
将约束放入目标函数中是一种隐式的约束,我们在迭代更新的时候不得不在满足KL散度差距和最大化或者最小化目标函数之间寻找一个平衡。这样做的好处是在代码实现的时候,不需要额外的处理KL散度,使用线性搜索,共轭梯度等等的方法对策略网络进行更新,代码实现更加简单。
另一种方法则是PPO截断,这种方法是目前PPO算法最受欢迎的实现方式。他直接省去了KL散度的计算,直接将新旧策略的差距限制在一个区间内。这使得代码的实现更加简单,同时效果也更好。
学习完PPO算法后,我阅读了DeepSeekMath这篇论文,DeepSeek的出圈,与这篇论文中提到的GRPO算法密切相关。GRPO算法是对PPO算法的改进版本,在RLHF中,使用PPO算法时,如下方的图片,我们需要维护四个网络(Reference Model, Policy Model, Reward Model, Value Model),奖励模型可以使用奖励函数,而参考模型通常是策略模型的未训练版本,但价值模型通常与策略模型的规模相当,因此它带来了巨大的内存和计算负担。GRPO算法,如下图,我们可以看到他直接取消了价值模型,这样一来我们可以认为只需要维护一个策略模型网络了。
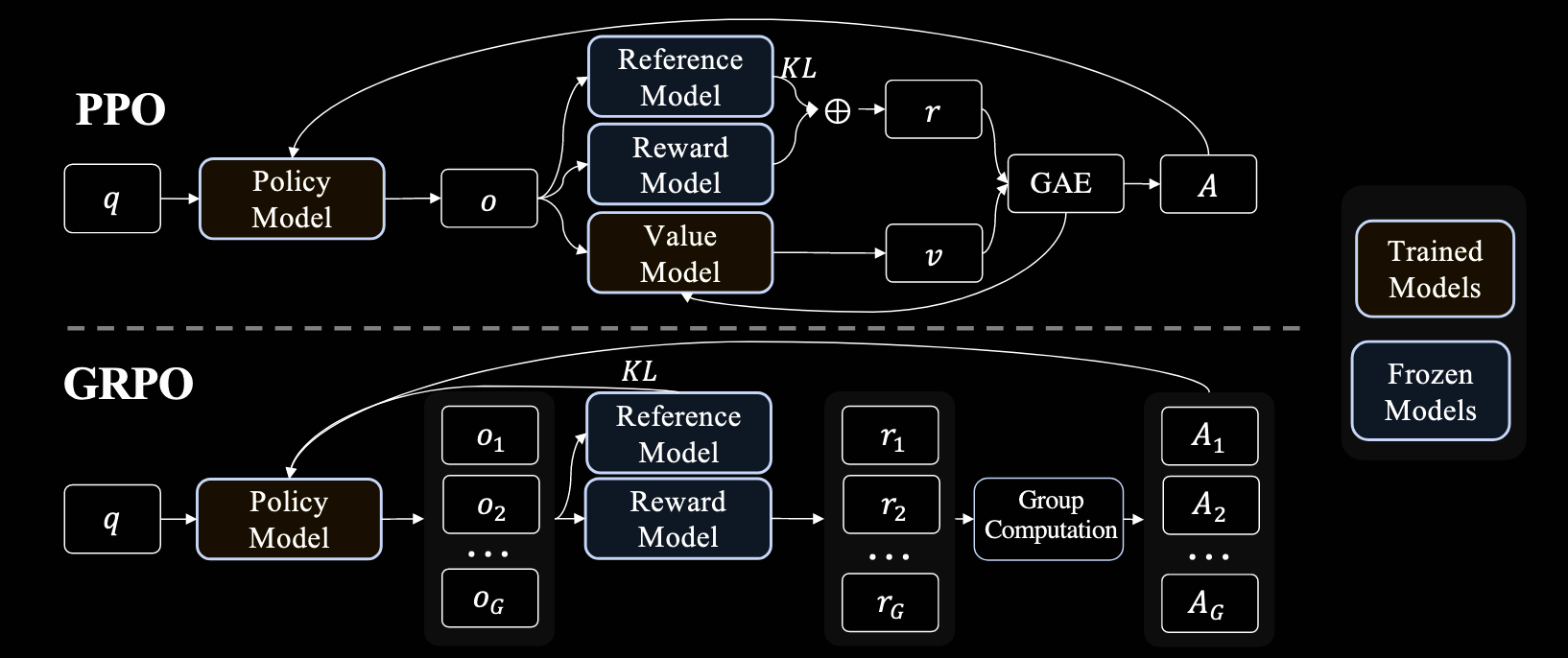
下面是DeepSeekMath论文中给出的GRPO算法的公式。GRPO算法的流程是,对于每一个Prompt,都生成生成一组输出(在代码中的实现通常是将Prompt复制多次,一次输入给模型)。对于每一组的输出,给其一个奖励,这个奖励不是token级别的,而是对于一整个完整的回答给一个奖励。因此,组内优势函数的计算也不是token级别的,而是通过标准化组内奖励来计算:
其中 $r_i$ 是第 $i$ 个响应的奖励,$\text{mean}(r)$ 和 $\text{std}(r)$ 分别是组内所有响应奖励的均值和标准差。这种标准化的方式确保了优势函数在组内具有零均值和单位方差,有助于训练的稳定性。我们再回到公式,对于每一个回答,我们在token级别上进行Clip以及KL散度惩罚,对一个回答进行期望计算,再在整个组内进行期望的计算。你会发现在GRPO中,和PPO不同的是,它同时使用了Clip和KL散度惩罚,这是因为Clip是约束新旧策略的差距,而KL散度惩罚是约束新策略和参考模型给出的策略。他们的作用各不相同,前者是确保训练更新的幅度,后者则是不希望模型经过强化学习训练之后,过于偏离原始的预训练模型,使得模型不会遗忘先前预训练的知识(毕竟常用的范式是SFT + RL)。
还有值得提到的一点是,论文中的KL散度计算利用了一个近似,同时这个KL散度是反向的,即是鼓励策略模型的分布精准覆盖匹配参考模型的分布,符合了希望模型不会遗忘预训练模型知识的目的。KL散度近似的公式如下:
感兴趣的可以参考下面的博客,里面有证明的详细过程,这也是论文中所引用的。
John Schulman’s approximating kl divergence