
Privacy-protected Retrieval-Augmented Generation for Knowledge Graph Question Answering
这篇文章大抵是詹密写的(不排除是串子或者詹黑,甚至这个可能性还大点?哈哈哈),证据见下图: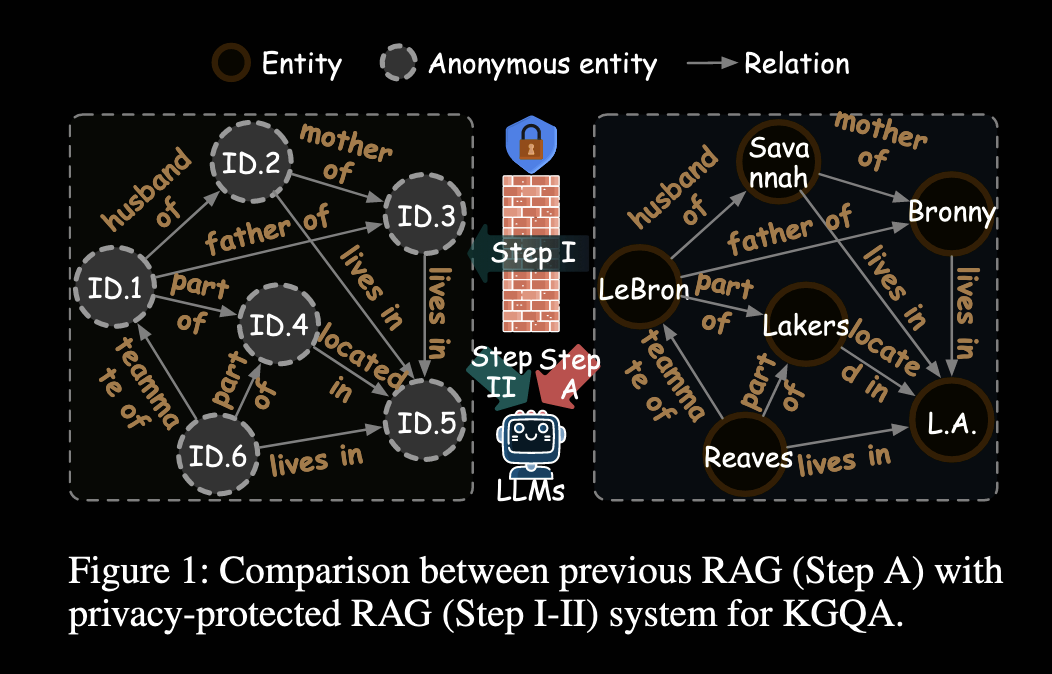
研究背景
调侃归调侃,即使是常务副Goat,也不能占用太大篇幅。
这篇 AAAI2026 论文讨论的是一个很现实、但之前在 KGQA 和 RAG 里没有被认真拆开处理的问题:如果知识图谱本身是私有的,里面包含个人隐私、企业内部信息,甚至是一些只能在本地保存的敏感实体关系,那么把这些三元组原样喂给大模型,本身就意味着泄露风险。传统 RAG 的基本假设是“把检索到的知识尽可能完整地提供给模型”,但在私有知识图谱上,这个假设恰恰是最危险的部分。论文开头用一个很直观的例子说明了这一点:如果问题是“Bronny 住在哪里”,传统 RAG 在检索阶段就可能把 (Bronny, lives in, L.A.) 这样的三元组暴露给 LLM。由于 LLM 往往是黑盒,而且还可能通过第三方 API 调用,用户既无法确认数据如何被缓存,也无法保证数据不会被进一步用于训练或日志分析,攻击者还可以通过特定的提示词注入,引导模型输出它原本不该输出的私密信息。
因此,核心约束很简单但影响很大,即知识图谱中的实体不再以真实名字出现,而是全部替换成对 LLM 来说毫无语义的匿名 ID,也就是 MID。这样做的好处是显而易见的,模型无法直接读到实体名称、实体描述和具体隐私内容;但坏处同样致命,因为一旦实体名被抹掉,传统 KGQA 或 RAG 里大量依赖“问题文本和实体语义对齐”的检索方式就立刻失效。换句话说,这篇文章真正要解决的不是“如何让模型少看到一点隐私”,而是“在几乎看不到实体语义的前提下,怎么还把检索和推理做对”。
论文要解决的核心问题
作者把困难总结成下面两个问题:
匿名实体如何转变为可被检索的信息。如果知识图谱中实体名称都替换为
m.01xx、m.02yy这种 MID,模型根本不知道它是人、地点、组织还是演唱会,也就无法把问题里的语义和图中的节点对齐。如何检索到相关的匿名实体。即使我们给匿名实体补上一点抽象语义,问题本身依旧是非结构化的自然语言,而 KG 检索更依赖结构匹配。如果问题和图谱之间没有一个中间层,检索仍然会很飘。
围绕这两个问题,论文提出了 ARoG框架(Abstraction Reasoning on Graph)。从名字就能看出来,这个方法的关键不是恢复真实实体,而是通过“抽象”重建足够用的语义和结构,使模型在不知道真实名字的情况下,仍然能够完成检索和推理。
相关工作
在相关工作部分,作者把现有 KGQA 方法大致分成两类:
Semantic Parsing。这类方法将 LLM 当成是“翻译器”,它的核心逻辑是将用户问题转换为数据库能懂的标准查询语句,再去图数据库里执行。代表方法如 KB-BINDER、TrustUQA 等。这类方法的优势是结构清晰,但问题也很明显:首先,它容错性极差,查询语句哪怕少一个括号或写错一个关系名,都无法得到正确答案;其次它严重依赖标注数据,性能高度取决于你给 LLM 提供了多少高质量的“问题-查询语句”对照示例(Labeled Exemplars)。
RAG-based KGQA。这也是近一两年更强势的路线,像 ToG、PoG、GoG 都属于这一类。流程分为检索和生成两个阶段,它们通常先在 KG 里迭代检索相关三元组,再让 LLM 基于检索证据生成答案。相比语义解析,这一路线更灵活,也更适合借助 LLM 的推理能力。但问题在于:首先,这些方法默认图里的实体和关系能被模型“看懂”,这意味着对于私有的知识图谱没有知识保护;其次,一旦实体全部匿名,这些方法的检索能力就会迅速下降,因为模型已经没法用问题语义去匹配实体;再者,如果 LLM 在检索前出现了幻觉,这些方法就永远找不到正确的三元组,检索会永远偏离。
方法解读
ARoG 的整体框架由四部分组成,前三个属于检索阶段,最后一个属于生成阶段:
- Relation-centric Abstraction,简称 RA
- Structure-oriented Abstraction,简称 SA
- Abstraction-driven Retrieval,简称 AR
- Generator
下面是结构图: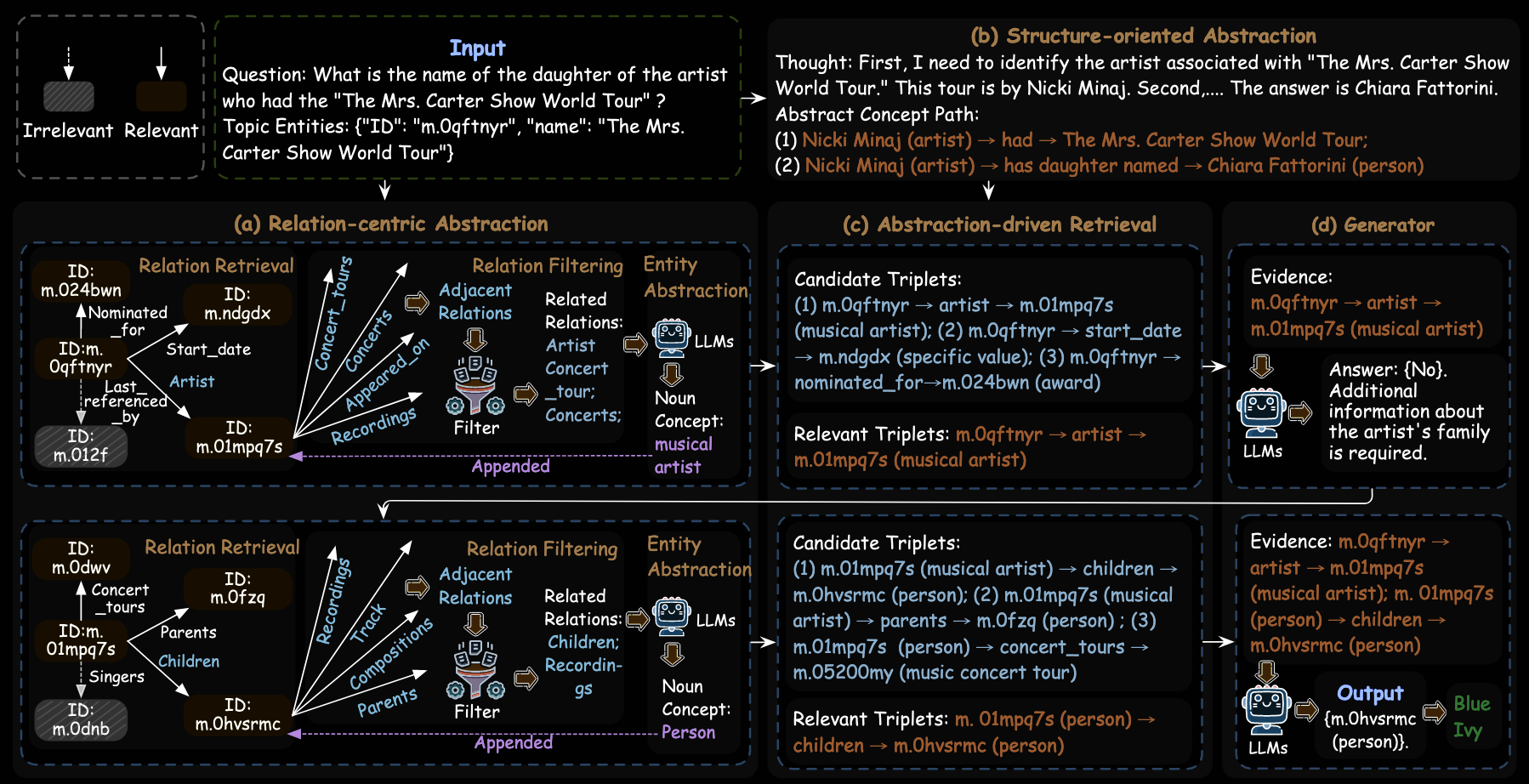
它的思路可以概括成一句话:先把匿名图谱和自然语言问题都投影到一个抽象语义空间里,再在这个空间里做检索和推理。这里最关键的是“抽象”二字。作者没有试图恢复真实实体名称,而是尽量恢复“足够支撑检索的高层概念”,比如把一个 MID 补成“某个人”“某个地理位置”“某类演唱会”等高层概念标签,再让问题也变成一条抽象概念路径。这样一来,匹配对象就从“问题 $\rightarrow$ 真实名词”转变为“问题结构 + 抽象概念 $\rightarrow$ 图谱结构 + 抽象概念”。
Preliminary
在预备知识部分,作者先按标准方式定义了 KG、KGQA 和三元组形式,然后明确了隐私保护设定。这里有一个细节很重要:ARoG 并没有完全封锁全部信息,而是保留了问题中的主题实体(Topic Entities)。例如问题里本来就提到了 “The Mrs. Carter Show World Tour”,那么这个实体名对模型是可见的;真正匿名的是图谱内部那些需要检索扩展出来的实体。这个设定兼顾了可用性和隐私性,是后续整个框架成立的前提。就算是走迷宫,也是知道起点的,完全匿名的话很多问题连起点都没法确定。
Relation-centric Abstraction
RA 模块对应第一个挑战,即“匿名实体怎么变得可检索”。知识图谱是提前构建好的,虽然实体名对 LLM 来说是匿名的,但实体周围的关系仍然存在于知识图谱中,并且保留了大量上下文语义。如果一个节点经常和 population、contained_by、time_zone 这类关系相连,那么即使不知道它叫什么,我们也很容易推断它大概率是地理位置;如果一个节点和 children、parents、recordings、concert_tours 等关系频繁连接,那么它大概率是 person 或 musical artist。
RA 模块分三步:
Relation Retrieval。从问题里的 Topic Entities 出发,先在 1-hop 邻域里收集邻接关系,再让 LLM 根据问题挑出最相关的
W个关系。这里的作用是先把无关分支裁掉,避免后面抽象时噪声过多。Relation Filtering。在候选实体簇确定后,作者进一步用 SentenceTransformer 计算“问题”和“关系”的 Embedding 相似度,只保留 top-K 的相关关系,论文里经验上设
K=5。这一层相当于用 Embedding 相似度再做一次细筛,减少仅靠 LLM 判断带来的随机性。Entity Abstraction。作者把保留下来的关系喂给 LLM,让它为匿名实体生成一个高层概念标签,然后把这个标签直接附加在 MID 后面,得到类似
m.xxx (person)或m.xxx (geographic location)这样的抽象实体表示。
在知识图谱中,顺着一个关系找下去,可能会得到一个实体簇(Entity Cluster)。例如顺着关系“NBA players”,可能找到多名 NBA 球员的 MID。出于性能的考虑,框架给予同一实体簇中的实体相同的高层概念标签(因为同一关系连接出来的实体,通常具有相似的语义属性),以减少 LLM 的调用次数,减少 Token 消耗。另一方面,在复杂的知识图谱中,一个实体通常具有多个不同的语义。框架的做法是将这些语义全部保留,用逗号连接起来,毕竟“只有小孩子才做选择题”。这样可以提升检索的精度,提供更强的语义特征。
Structure-oriented Abstraction
如果说 RA 是给图谱里的匿名实体补语义,那么 SA 就是在给问题补结构。作者认为,单纯使用自然语言问题去匹配抽象实体仍然不够稳定,因为问题往往是自由表达,而图谱检索更依赖关系链和路径结构。因此,SA 模块会把问题转成一个抽象概念路径(Abstract Concept Path)。
论文里的例子很典型。对于问题“What is the name of the daughter of the artist who had The Mrs. Carter Show World Tour?”,模型不会直接去找实体名,而是先通过 CoT 风格提示词,把问题转成两条抽象路径:
Nicki Minaj (artist) -> had -> The Mrs. Carter Show World TourNicki Minaj (artist) -> has daughter named -> Chiara Fattorini (person)
这两条路径里的实体甚至可能是错的,但只要路径结构和抽象概念是对的,检索仍然可能成功。因为图里真正要找的是“某个 artist 和某个演唱会之间的关系”以及“该 artist 与其 daughter 之间的关系”,而不是 Nicki Minaj 这个名字本身。
这说明 SA 的价值不在于直接产出答案,而在于把问题转换成一种更适合图谱对齐的中间表示。相比裸问题文本,这种表示兼具结构信息和概念信息,尤其适合多跳检索。
Abstraction-driven Retrieval
有了 RA 生成的抽象实体,以及 SA 生成的抽象概念路径,AR 模块就可以正式工作了:本质上是一个多轮迭代检索过程。
这里定义了两个超参数:width W 和 depth D。W 表示每一轮最多保留多少条关系/候选,D 表示最多做多少轮扩展。每一轮里,模型都会从当前 Topic Entities 的 1-hop 子图中构造候选抽象三元组,再计算这些三元组与问题抽象路径之间的 Embedding 相似度,选出最相关的 W 条作为证据,并把其中新发现的实体作为下一轮的起点继续扩展。
和传统 RAG 相比,这一模块最大的不同在于:它不再让 LLM直接基于匿名实体做检索决策,而是依赖“抽象后的三元组”和“抽象路径”之间的语义相似度来检索。这样做有两个好处:
避免了把大量匿名实体直接丢给 LLM,让模型在看不懂实体的情况下硬猜。
把多跳检索转化成了一个更稳定的“抽象匹配”过程,尤其适用于隐私设定下的复杂问题。
Generator
生成模块相对直接。作者把问题原文、当前累积到的证据三元组、指令和范例一起交给 LLM,让模型同时输出一个 Flag 和最终答案 Ans。如果 Flag 表示证据还不够,就继续进入下一轮检索;如果足够,就输出答案。
这里还有一个现实层面的设计:模型生成的答案里可能仍然包含 MID,这些 MID 不在云端解码,而是在用户本地通过一个 Privacy Map 映射回真实名字。对真正的私有 KG 场景来说,这一点是必要的。
实验设计和结果
实验使用了三个经典 KGQA 数据集:WebQSP、CWQ 和 GrailQA。三者的难度分布很有代表性。WebQSP 更偏简单事实问答,很多答案在 1-hop 子图内就能找到;CWQ 更强调多跳推理;GrailQA 则包含更多长尾知识(指那些极其冷门、专业性强、或者只存在于特定私有领域中的知识),对泛化和复杂检索要求更高。
作者设计了两种测试设定:
#Total:在完整测试集上评测#Filtered:过滤掉那些单靠模型本身知识以及 CoT 提示就能答对的问题,只保留真正需要从私有 KG 检索额外知识的问题
我觉得 #Filtered 这个设置尤其重要,因为它更接近论文真正关心的隐私场景。如果一个问题本来就在 LLM 预训练知识里,模型答对并不能说明私有 KG 检索做得好;只有在模型必须依赖私有知识时,方法的价值才真正体现出来。
实现上,作者使用的是 GPT-4O-MINI-2024-07-18,SA 和 Generator 温度设为 0,RA 温度设为 0.4,这样做是为了在 RA 阶段增强语义的捕捉能力(这样才有能力给同一实体打不同高层概念标签)和确保与 SA 阶段对齐(防止检索阶段距离过远,比如前者生成“艺术家”,后者生成“歌手”,由于温度为 0 而始终无法对齐),而在 SA 和 Generator 阶段确保每次输出不变;将频率惩罚系数和存在惩罚系数设置为 0 也是为了语义的一致性;检索宽度和深度默认都设为 3,并重复实验 3 次取平均。
主实验结果
主结果表非常说明问题。ARoG 在三个数据集、两种设定下全部取得最好结果。
在 WebQSP 上,ARoG 达到 74.7 / 58.9;CWQ 上达到 60.0 / 36.3;GrailQA 上达到 78.7 / 71.8。这里前一个数字是 #Total,后一个是 #Filtered。
更关键的是相对提升。相比第二名,ARoG 在六项指标上的绝对提升分别为 +6.1、+5.8、+4.9、+19.8、+16.4、+9.0。其中 CWQ 和 GrailQA 的 #Filtered 提升尤其夸张,说明一旦进入“必须依赖私有知识、实体又匿名”的严格场景,传统方法就很难工作,而 ARoG 的抽象机制恰好对这个设定最有效。
从对比组来看,Pure-LLM 方法在 #Filtered 设定下普遍崩得很厉害,比如 CoT 在三个数据集上直接掉到 0;RAG 基线如 ToG、GoG、PoG 也都显著下降,因为它们没法处理匿名实体带来的检索失真;SP 路线相对更稳一些,但在没有规范的查询语句就直接罢工了,且整体上限仍然比不过 ARoG。
我还注意到 Pure-LLM 方法下使用 CoT 反而还不如 LLM 直接输出,我个人认为是在匿名实体的知识图谱下,CoT 使得大模型有严重的幻觉,使得检索逐步偏离问题。
消融实验
消融实验主要验证了 RA 和 SA 两个模块是不是都必要。
先看 RA。由于 RA 的第二步是在第一步的前提下,从而增强第三步,消融实验没有考虑保留第二步的情况下去掉第一步和第三步。同时因为第一步是后面两部的基础,所以不考虑只有第三步的情况。从实验结果看,三个数据集在 #Total 设定和 #Filtered 设定下性能均降低。这说明 RA 几乎是整个系统的基础,这一阶段不完整,后续检索就会明显失效。
再看 SA。在相同条件下去掉 SA 后,性能也会明显下降,尤其在 CWQ 上更严重。作者据此认为,SA 更擅长处理多跳问题,因为它提供的是路径级别的结构约束,而不是单纯的语义提示。换句话说,RA 更像是在解决“节点可读性”,SA 更像是在解决“问题结构化”,两者分别对应了论文开头提出的两个核心挑战。
效率分析
很多这类方法会有一个担忧:你加了这么多抽象步骤,会不会成本很高?论文专门做了效率比较。
从总 Token 开销看,ARoG 并不离谱。WebQSP 上总 Token 为 7752.1,和 ToG 的 7713.4 很接近;CWQ 上是 11242.1,虽然高于 ToG 和 PoG,但显著低于 GoG;最有意思的是 GrailQA 上,ARoG 反而最低,只有 5605.5,比 ToG、PoG、GoG 都省。这说明抽象检索虽然多了一些步骤,但它减少了很多无效扩展,在复杂任务上甚至更省。
参数分析里,作者把宽度 W 和深度 D 都从 1 调到 4。结果显示,WebQSP 对宽度更敏感,对深度不太敏感,因为很多问题在 1-hop 内就能解决;CWQ 和 GrailQA 则宽度、深度都有效,但当深度超过 2 后收益开始减弱,因为大部分答案其实也不会超过 2-hop。这个结论挺符合直觉,也说明作者的方法不是靠无限扩图取胜,而是在较小搜索半径内把匹配质量做高。
深入分析:为什么“抽象路径”比 CoT 和问题分解更适合这里
作者还把 SA 模块和两种替代策略做了比较:一种是直接使用 CoT Rationale,另一种是 Question Decomposition,把复杂问题拆成多个子问题。结果 ARoG 都更强(注意,论文中 ARoG 也是使用 CoT,强制最后生成符合结构的抽象概念路径,这个实验中的 CoT 是直接生成解释性文本)。
原因也不难理解。CoT 虽然能提供推理线索,但它输出的是解释性文本,不一定适合和抽象三元组做结构对齐;问题分解虽然更有结构,但如果没有“抽象概念”这一层,匿名实体仍然难以匹配。ARoG 的 Abstract Concept Path 相当于同时拿到了“结构”和“概念”两张牌,所以在 Privacy-protected KGQA 里更合适。
论文最后还设计了不同隐私暴露场景,包括只在检索阶段暴露实体、只在生成阶段暴露实体、两阶段都暴露,以及完全私有场景。结果显示,ARoG 在不同场景下都更稳,而依赖 LLM 直接处理匿名实体的变体 ARoG-R(与 ARoG 的区别通俗来说就是 AR 阶段前者是 LLM 直接处理,后者是向量相似度匹配)和 ToG 都会在某些场景显著掉点。这进一步说明 ARoG 的鲁棒性并不只是“某个特定 Setting 调得好”,而是方法层面确实更贴合匿名 KG 的约束。
总结与思考
这篇论文最有价值的地方,我认为不只是提出了一个新框架,而是明确提出了一个此前经常被忽视的问题设定:当外部知识是私有的,传统 RAG 的“把证据原样交给 LLM”并不安全。
ARoG 给出的答案很有启发性:既然不能把真实实体暴露给模型,那就不要执着于恢复实体本身,而是退一步,只恢复检索所需的抽象概念和关系结构。实体层面保留匿名,语义层面补一个高层概念,问题层面再变成抽象路径,最后用抽象匹配做多轮检索。这是一种非常有思想的折中方案。
说到这篇工作的不足之处,我觉得抽象概念的质量很依赖 LLM 本身的泛化能力,不论是生成高层概念标签还是抽象概念路径。可以在框架的基础上,增添一个回溯机制,防止因跳错节点而导致的错误累积。
另外,在我跑了项目代码以及和学长讨论过后,我们觉得论文的方法其实比较复杂,导致检索的效率并不高(实测下来前两个问题平均一个就要将近两分钟),而且一开始的假设也存在不足——论文认为真实实体是绝对不能暴露给大模型的,但是关系可以。但现实生活中,关系其实也蕴含了很多隐私内容,后续工作可以从这里入手,如何在保护实体和关系的同时,能做到准确的信息检索。