
Human-in-the-loop Learning for Adaptive Robot Manipulation using Large Language Models and Behavior Trees
26年年初的OpenClaw,像是一颗核弹轰炸了AI圈。网上随之出现各种上千元的上门安装服务,甚至后来热度稍微下去之后(太烧token,普通人玩不起,以及存在安全问题),出现了500元的上门卸载服务,商业头脑这块我还是太欠缺了,怪不得人家能赚钱……
OpenClaw和具身本体的结合也是目前一大研究热点。目前一个可行的想法,也是我目前正在研究的是,Agent针对特定任务进行规划,规划使用行为树表示,传给具身本体,按照行为树流程执行对应的操作。
什么是行为树?
行为树(Behavior Tree)是用来实现非人工角色复杂行为的工具,它具有下面这些特征:
- 行为树是树,执行时从根结点开始按照指定的顺序遍历,直到到达终结状态。
- 叶子结点都是可执行的行为,可以是一个简单的检测操作,也可以是一个更复杂的操作,结点会返回状态信息(Success,Failure,Running)。
- 内部结点控制树的遍历,会根据孩子结点返回的状态信息,按照特定的规则确定下一个执行的结点。
关于行为树的原理,具体表示,如何实现,和有限状态机之间的对比,大家可以参考下面这篇博客,看完对行为树就有基本的理解了。
Introduction to behavior trees
方法解读
了解什么是行为树之后,回到论文本身。这篇IROS文章提出了一种Human in the loop的上下文学习方法,用户反馈被用来指导LLM纠正和完善动作知识,确保其准确性和安全性。生成的动作知识可以直接用于自适应操作,无需知识转移的努力,使机器人能够完成任务并处理外部干扰。
许多研究将LLM运用于机器人中,来实现指令跟踪任务。然而,当遇到外界干扰时,这种方法涉及反复调用LLM进行处理,效率很低。在具身智能领域一个很前沿的研究方向是将LLM和行为树进行结合,可分为两种技术方向。第一种方法是根据用户的指令直接生成行为树的代码,这种方法需要大量的数据对LLM进行微调,而且当环境发生变化,当前的行为树不可用,需要重新调用LLM生成,效率比较低。第二种方法是使用行为树规划器,LLM先生成最基础的行为树,然后使用行为树规划器进行扩展(这是行为树规划器的核心,将不满足的条件扩展为子树,利用提前构建的动作知识库执行对应操作来满足条件),这样可以调用较少次数的LLM处理外界的扰乱。缺点就是动作知识库是提前构建好的,当任务无法通过构建好的动作知识库解决时,需要增量学习的能力以及扩展动作知识库。
解决增量学习和扩展能力的问题,可以通过常用的强化学习,模仿学习和无监督学习的方法。但强化学习需要大量训练以及精心设计的奖励函数,而模仿学习需要大量的专家数据轨迹,无监督学习则很容易偏离预期。因此,论文提出了一种Human in the loop的学习机制,通过用户反馈修正,使LLM可以生成动作知识库以外的动作知识,并加入到动作知识库中。下面是论文中方法的流程图:
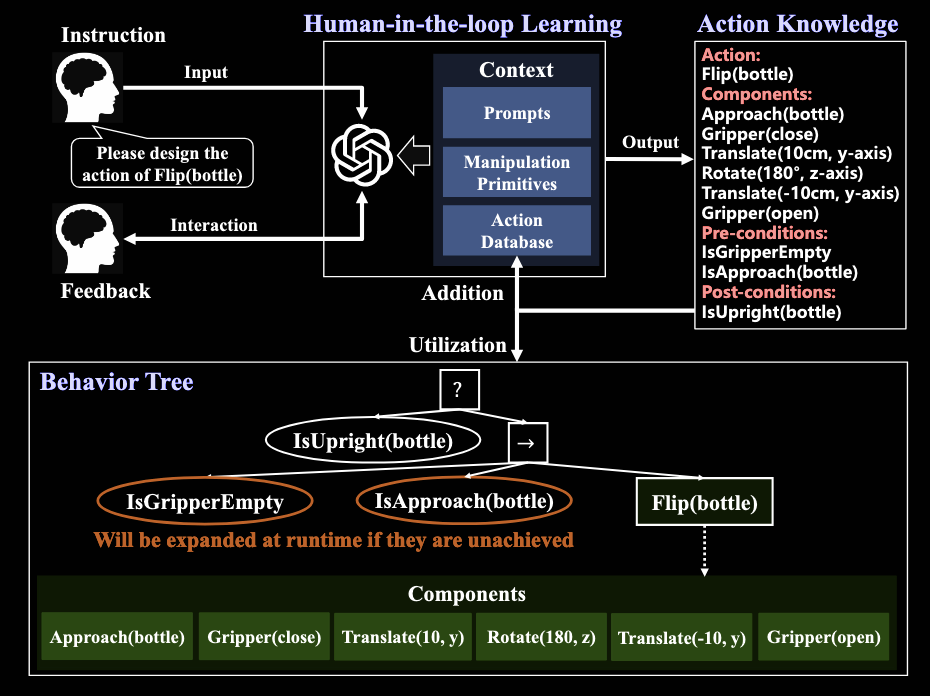
左侧图片是整个workflow,右侧图片是Human in the loop的学习机制。从左侧的workflow中可以看到,上下文中包括提示词,动作知识库,以及操作原语。操作原语是最底层的,是完成一个动作的全部操作指令的组成。每一个动作知识都包括动作,动作的前置条件,动作的后置条件以及一系列操作原语。这里有一个细节,在行为树中,动作知识的后置条件在左侧子树,而前置条件在右侧子树,具体动作则在右侧子树的最后一个叶子结点。这是因为在具身本体底层,按照行为树执行对应的操作时,采用的是类似于轮询(Pooling)的方式,对应的变量称之为Tick。每经过一个Tick,就会从行为树的根节点出发,沿着树的分支一路往下走,遇到叶子节点就会询问当前叶子的状态,得到状态反馈(Success,Failure,Running)后停止。因此,后置条件需要放在左侧子树,如果后置条件全部满足,则不需要执行右侧子树,因为此时代表动作已经完成。而只有当后置条件没有完成,执行右侧子树时,没能达成的前置条件会被扩展为子树。
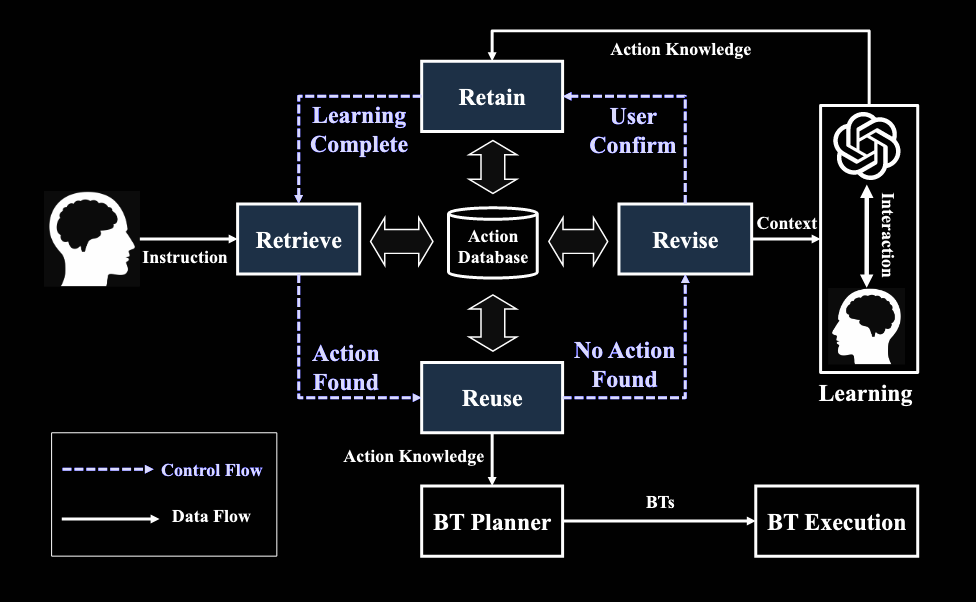
Human in the loop学习机制分为四个阶段:检索(Retrive) -> 复用(Reuse) -> 修改(Revise) -> 保留(Retain)。当用户下达指令,首先进入检索阶段,如果动作知识库中有完成任务所需要的动作知识,将直接进入复用阶段,执行行为树;如果动作知识库中没有完成任务所需要的动作知识,将进入修改阶段,此时LLM会通过上下文学习,生成新的动作知识,展示给人类,通过多轮交互,人类用自然语言指出动作知识中的问题引导LLM进行改正,当人类任务动作知识合理且安全后,进入保留阶段,将新生成的知识加入动作知识库中,接下来就是重复一遍检索成功的流程。
实验结果
第一部分实验是测试Human in the loop机制对于任务执行成功率的提升,论文使用了Deepseek-V3和ChatGPT-4o这两个主流大模型,以仅学习上下文以及提前构建好的动作知识库完成用户指令作为baseline,进行对比实验。结果表明,在八个不同的任务中,通过人类反馈纠正动作知识,成功率均达到了80%以上。
第二部分实验是抗干扰测试。论文为八个任务设置了一共十六种干扰,利用Human in the loop学习机制,遇到干扰相当于是动作的前置条件不满足,行为树规划器会将该条件扩展为子树,生成新的动作知识移除扰乱,继续完成原来的任务。结果表明在八个任务中,面对扰乱仍然有70%的成功率。
第三部分实验是泛化能力测试,将八个任务中的操作对象进行替换(比如方块变成扁的长方体,盒子的高度变高,插入的孔变小等等),结果是喜忧参半的。堆积木,按按钮,扶正水瓶和搭房子这四个任务的成功率达到了70%,但是插孔,拧瓶盖,拉出抽屉和拿出盒子中的物块这四个任务的成功率不足40%。
不足与思考
论文中不止一次提到了LLM在空间理解能力上的不足,在当时论文那个时间,vlm还不够成熟,所以需要人的介入来判断大模型生成的动作知识是否合理且安全,也就是论文所提到的方法。这种方法极度依赖人的介入,涉及到人就比较主观,能不能做出正确判断和人的业务能力水平紧密相关。
LLM在空间理解能力上的不足,也就导致放入动作知识库的动作知识中的参数,LLM在后续的调用中是基本不会修改的。这就导致在第三部分的实验中所体现的泛化能力差。比如将大抽屉替换为一个小抽屉,LLM还是根据大抽屉的参数拉出小抽屉,这就导致了小抽屉一下子就整个被拉出。
论文中还提到目前的方法不适用的长程任务和复杂操作。对于长程任务,LLM很难一次性生成一条超长的无错动作链,并且单次推理的上下文窗口是有限的,执行长程任务很容易导致中间的过程被遗忘(LLM对上下文窗口的头尾部分注意力较高),产生幻觉。对于复杂操作,仅通过人类的指令,LLM很难生成准确的策略和操作原语的顺序。
对于以上问题,论文最后也提出了未来的改进,比如对LLM针对长程任务进行微调。还有进行强化学习训练,例如一些复杂的操作,LLM无法生成准确的策略和操作原语顺序,可以通过强化学习让具身本体进行试错,最后得到一个复杂操作的策略,打包为一个新的操作原语。
我个人认为,结合Agent是一个不错的思路。现在vlm有了很大的进步,Agent本身可以使用一个多模态大模型或者给Agent一个视觉工具,弥补空间能力上的不足。面对不同的操作对象,Agent可以先进行分析,修改动作知识库中动作知识的参数,再执行行为树,提升泛化能力。而对于长程任务,Agent具有短期记忆,同时可以使用向量检索库赋予长期记忆(Spacial RAG),来解决长程任务中的遗忘问题。
目前我现有的想法是,使用OpenClaw或nanobot操控具身本体,通过编写一个Skill告诉Agent如何构建动作知识,以及从动作知识库中提取动作知识时,调用视觉工具对参数进行修改,提高泛化性。Agent将动作知识以JSON格式的行为树发送给具身本体,在具身本体将JSON解析为xml文件,使用行为树的库(py_tree或BehaviorTree.CPP)执行行为树。对于长程任务则构建记忆系统(比如最近的一个热点,前面提到的Spacial RAG)。此外,可以在沙箱中配置mujoco等仿真环境,Agent构建动作知识后,可以在仿真环境中执行行为树,若在仿真环境中能成功完成,则操控真机执行;若不能完成,返回问题并让Agent修改策略,操作原语的顺序或参数。这样可以减少对Human in the loop的依赖,只有当仿真环境通过但真实环境出错(SimtoReal Gap),才让人类介入。至于这个想法是否可行,等我在未来的科研研究中揭晓哈哈哈哈哈!