
Autobots, assemble!
暑假开摆了许久,最近有了一些学习的动力,终于终于终于刷完了Andrej的课,学习到了当下大语言模型最主流的架构——Transformer。这篇博客主要则是记录我在学习Transformer模型以及通读“Attention is all you need”论文后的一些个人思考和总结。你应该发现了标题是“Autobots, assemble”,如果你和我一样是变形金刚的狂热粉丝,你应该能get到这个小彩蛋。
自注意力机制 Self-attention
在Transformer架构推出之前,人们主要采用的是CNN和RNN架构,在论文前言部分,就提到了RNN架构的问题。首先他是一个时序模型,当前词语的隐藏状态是由前一个词语的隐藏状态和当前词语所决定的。换句话说,如果前面词语的隐藏状态没有计算出来,我们就无法预测下一个词。这种时序模型的计算性能很差,因为他没有办法并行处理。其次这些随着时序一步步记录的每个词语的隐藏状态,随着模型的训练可能会失真,而想要避免失真只能讲隐藏矩阵进一步扩大,但与此同时也会带来巨大的内存开销。
Transformer中的自注意力机制,则很好的解决了RNN架构中出现的这种问题。它选择使用缩放点积注意力。我们首先接受一个输入,得到他的词嵌入矩阵和位置嵌入矩阵的和,然后我们利用三个可训练的权重矩阵WQ,WK,WV生成查询向量,键向量和值向量。Query则表示“提问者”,即当前所需要关注的问题,用于与其他位置的Key匹配相似度。Key表示其他位置的标识,用于与Query计算关联度。Value则表示实际存储的信息,根据Query和Key的相似度加权求和后输出。自注意力机制的公式如下:
我们知道,两个向量越相似,在对方的投影这越大。因此,使用向量的点积可以很好的表达相似度这一概念,当前词块可以从中知道需要融合更多哪个词块的信息。同时我们可以看到,softmax函数中还除以了$\sqrt{d_k}$,即键向量的维度,这么做是为了防止矩阵的方差过大,和归一化中的操作是一样的。
多头注意力机制 Multi-head Self-attention
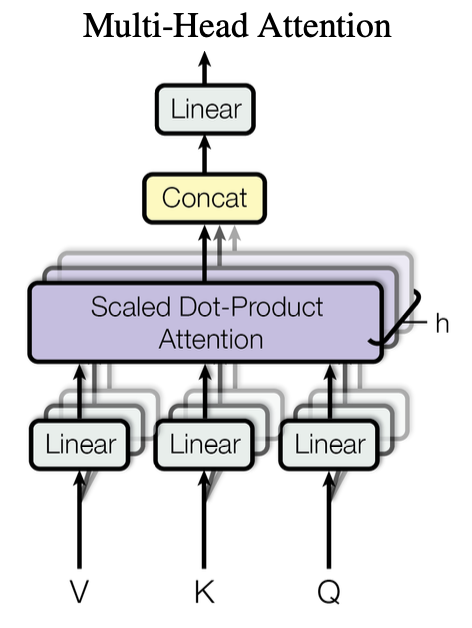
开头我们提到,Transformer架构相比于RNN,它的优点在于并行计算。多头注意力机制的核心就在于,将关联度矩阵投影到多个低维度的向量中,让这些向量并行计算,以扩展模型专注于不同位置的能力。相当于给了模型多次机会学习不同的投影方式,然后将每次学习到的关联度矩阵连接在一起,再做一次投影整合全部的信息,可以类比于CNN中的多个输出通道。
交叉注意力机制 Cross-attention
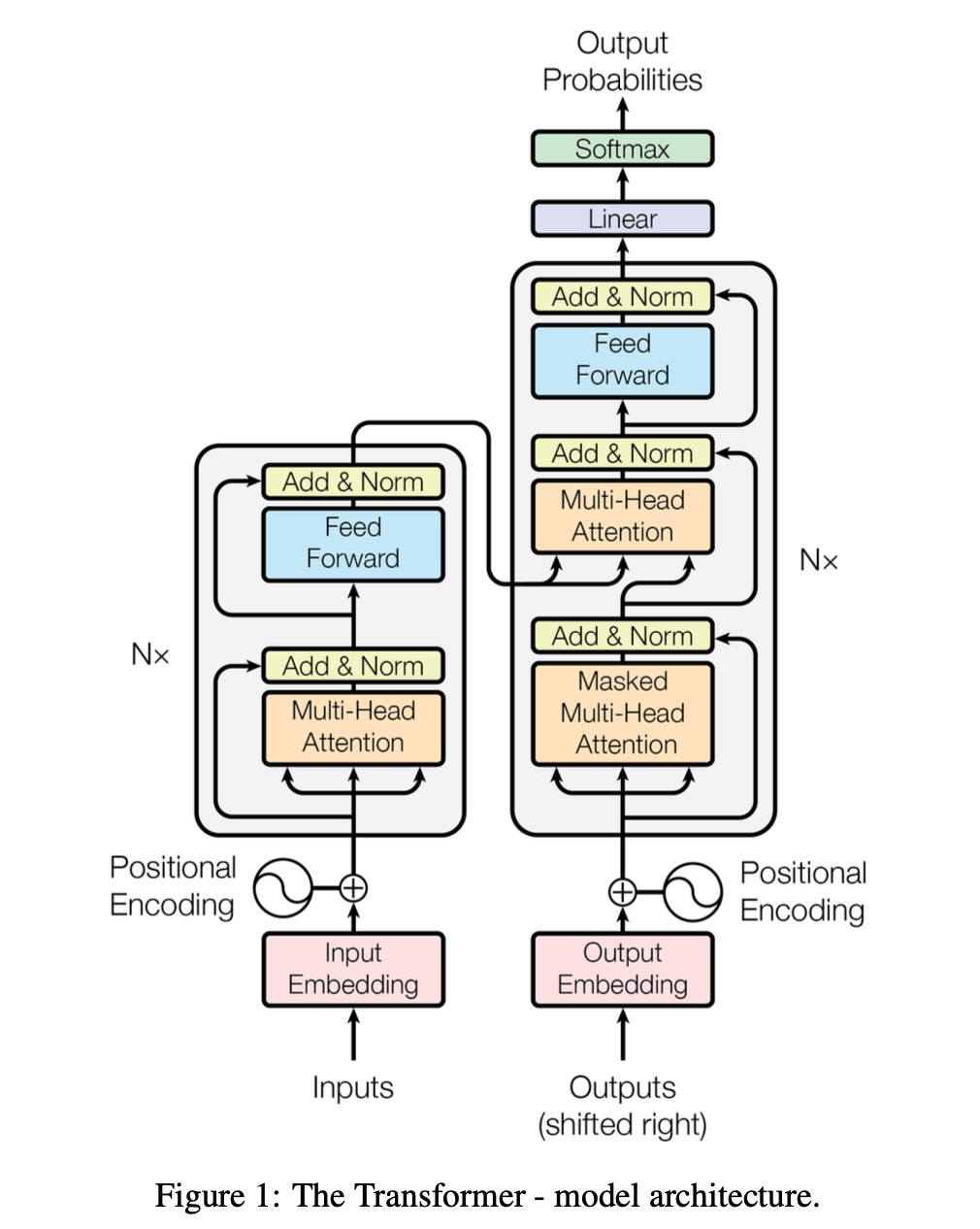
论文中提到,Transformer架构其实是为了机器翻译而设计的,这也是Transformer架构图是由编码器和解码器共同组成的原因,当然这两者并不是一定要绑定在一起,Andrej的Zero to Hero课中实现的gpt2只需要学习文本生成文本,不需要编码器,在未来也会学习到很多编码器和解码器单独应用的模型架构。每一个编码器和解码器模块都由多头注意力和前馈层组成。要注意的是,在解码器中,多头注意力是Masked的,因为在解码的过程中,每一个词块只能注意到历史的词块,通过注意力机制得到与历史词块之间的关联度矩阵。模型是为了学习训练集,预测生成下一个词块,所以在解码器中是不能注意到未来词块的信息的。因此,我们要利用一个下三角的矩阵,将关联度矩阵每个词块与未来词块的关联度设置为0。相反,在编码器中,需要全知性,需要全局捕捉输入序列的双向依赖关系,因此允许每个位置关注序列中的所有其他位置。
回到正题,交叉注意力机制大体上和多头注意力机制一样,区别在于注意力机制中Q,K,V的来源。Query的来源是解码器,是一个需要补充信息的目标序列,而Key和Value的来源则是编码器,是一个提供信息的参考序列。这样的设计使得模型可以让两个不同的序列建立联系,从而实现信息的融合。
掩码 Mask
Transformer中,掩码主要解决的是下面两个问题:
- 避免偏差
- 防止偷看
对于避免偏差,由于在同一个batch中会包含多个不同长度的文本序列,过长的我们会进行截断,过短的则需要补充,我们称之为Padding,通常会填充数字0。此时问题就发生了,注意力机制会计算这个数值0,考虑填充位置上的信息,对最后的注意力分数产生影响(softmax之后数值变为1)。
解决方法很简单,就是在softmax之前应用一个掩码矩阵,称之为Padding Mask,矩阵中填充词的位置放一个足够大的负数,其余位置为0。这样一来经过softmax激活函数后,得到的注意力分数会归0或接近于0。
对于防止偷看这个问题,在上文解码器中有所提及。因为解码器中不能预知未来,只能获取自己之前的信息,所以我们需要一个三角矩阵,将上三角部分全部置0,我们称这个三角矩阵为Sequence Mask。
前馈层 Feed Forward Pass
在编码器和解码器中,均存在一个前馈层。前馈层实际上就是一个MLP的架构,他的主要作用就是对关联度矩阵中的特征信息进行非线性的变化和增强(论文中提到将神经元的数量放大到原来的四倍,经过ReLU/GeLU函数进行非线性变换,最后变换为输入时的shape),让模型具有更强大的表达能力。
位置编码 Positional Embedding
再回到上面Transformer的架构图,你会发现在第一层Embedding和进入编码器/解码器之前,都会进行位置编码(Positional Embedding)。你可能会问:“词嵌入矩阵已经提供基础的语义信息了,注意力机制可以捕捉长距离元素之间的依赖关系,为什么还需要位置编码呢?”
这是因为Transformer架构是置换等变。这意味着如果你打乱输入序列的顺序,输出序列会以完全相同的方式被打乱。例如将输入“我喜欢你”修改为“你欢喜我”,输出也会从“I like you”变为“you like I”。所有模型并不关心元素在序列中的绝对位置或相对位置,而位置对于语言来说至关重要,“我喜欢你”和“你喜欢我”这两句话显然是不等价的,因此引入位置编码,给模型一个关于顺序的提示。
论文中使用的是正余弦编码,公式如下:
其中:
- $pos$ 表示词在序列中的位置
- $i$ 表示词向量的维度索引,取值范围为$[0, d_{model}/2 - 1)]$
- $d_{model}$ 表示词向量的维度
这种方式为不同维度创建了不同的波长,当i比较小时,波长短,函数变化快,有助于捕捉近距离关系,高敏感性;当i比较大时,波长长,函数变化慢,有助于学习长距离依赖关系。
与Andrej在课中实现的不同,这种编码是不可训练的,在模型开始这个数值就已经确定,加入到词嵌入矩阵中;而Andrej在课中使用的是可训练的位置矩阵。前者可处理更长序列,后者只能处理训练时见过的长度,适应性差。
无论是论文中使用的正余弦编码,还是Andrej课中使用的位置矩阵,都属于绝对位置编码。除此之外,还有相对位置编码,使用相对位置,当两个文本平移一段距离,他们之间相对位置不变,可以有效过滤掉绝对位置编码带来的无关信息。
和绝对位置编码作用在词嵌入矩阵不同,相对位置编码主要作用于注意力机制中,目前使用最多的相对位置编码是旋转位置编码(RoPE),公式如下:
首先将向量两两配对,看作一系列二维平面,给定一个绝对位置(p),对于第 ( i ) 对维度 ( (2i, 2i+1) ),我们定义一个旋转角:
其中(base是控制频率范围的超参数):
对于任意一个向量 ( x ) (( Q/K )),其位于第 ( i ) 个二维平面上的分量 ( (x{2i}, x{2i+1}) ) 会被旋转 ( \theta_{p,i} ) 角度:
等价于复数运算:将 ( x{2i} + j \cdot x{2i+1} ) 乘上 ( e^{j\theta_{p,i}} )。
当(Q)和(K)都经过旋转位置编码之后,注意力计算公式即变为:
其中关键的内积公式变为: